
Othman Moumni Abdou - Ingénieur data senior
La complexité d’anticiper et piloter ses coûts d’infrastructure cloud
Le monde d'avant :une infrastructure cloud, mais de nombreux paramètres
Si vous avez commencé à mettre en œuvre un projet de données IoT, vous avez peut-être rencontré des difficultés pour estimer précisément les coûts du cloud lorsque le projet sera déployé sur 1, 10 ou 100 équipements. En effet, un tel projet implique plusieurs capacités : transmission, stockage, traitement des données au moins. Chez les fournisseurs de cloud établis comme Azure ou AWS, la tarification de ces produits est complexe : non seulement elle est basée sur plusieurs paramètres (par exemple : CPU, RAM & Gigaoctets) mais parfois certains de ces paramètres ne sont pas prévisibles et vous n’avez pas d’autre choix que d’accepter le prix final sur la facture. En conséquence, cela peut ralentir le début du projet ou mettre en péril sa viabilité financière.
Chez InUse, le modèle de tarification de notre solution s’appuie sur deux principes fondamentaux :
C’est pourquoi notre offre de stockage standard se compose de :
Dans cette offre, un “gigaoctet” intègre le coût de stockage mais aussi les coûts de transmission et de traitement des données. Le fait de disposer d’une mesure intégrée unique rend le modèle beaucoup plus prévisible et simple à comprendre. Bien entendu, nous vous fournissons toutes les mesures pour suivre votre consommation en temps réel sur la plateforme.
Dans notre dernière version, nous avons lancé un nouveau module de pilotage du stockage des données afin que vous puissiez avoir une vue plus détaillée de votre consommation actuelle.
L’architecture de notre solution peut être résumée comme suit :
La consommation de données est la somme de ces trois composantes. Vous pouvez voir une capture d’écran de la nouvelle interface et des trois catégories mentionnées précédemment : Models représente la base de données analytique, Databases pour le stockage brut des données et Files pour le stockage des fichiers.
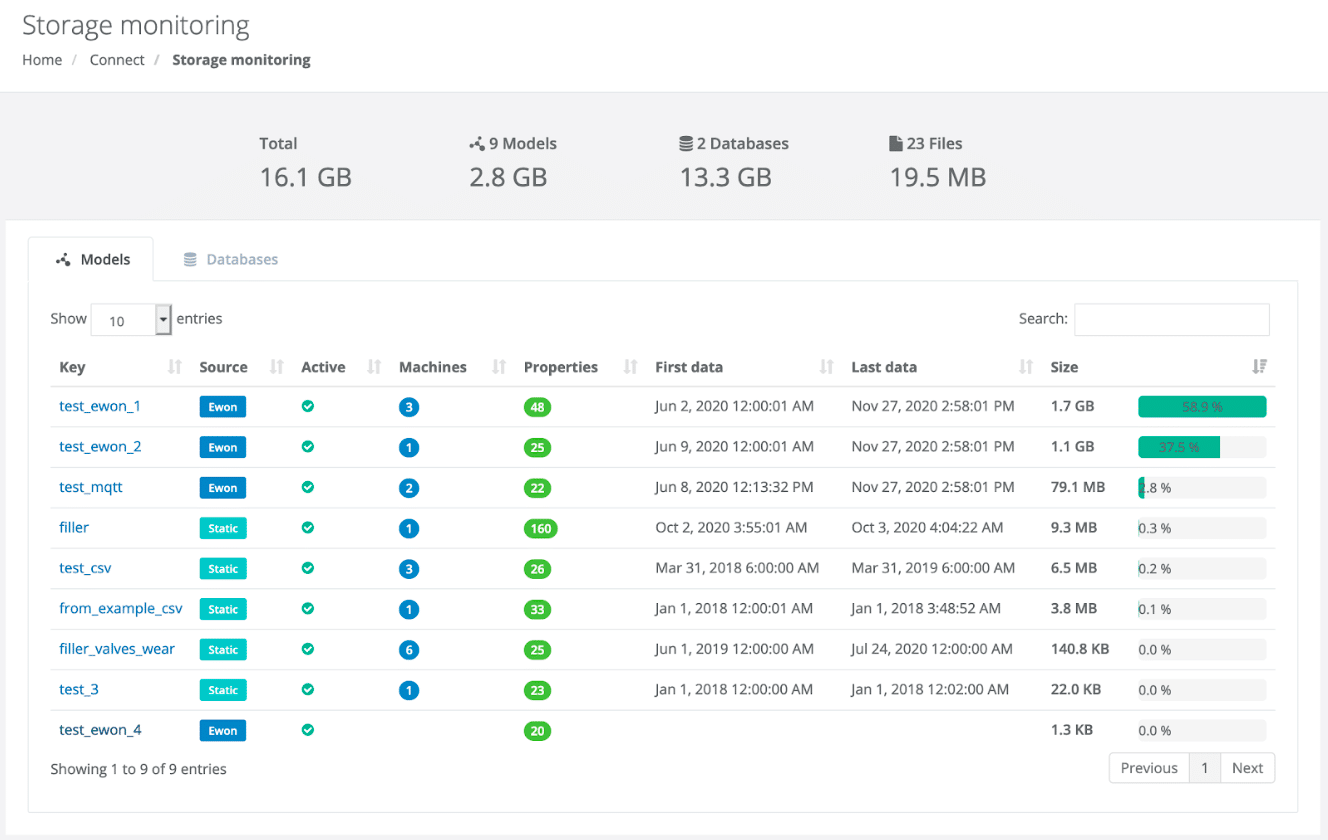
Des statistiques sur les stockages de données sont calculées toutes les heures et celles-ci sont historisées.
L’objectif de ce service est non seulement d’avoir une meilleure visibilité sur l’utilisation du stockage et son évolution dans le temps, mais aussi de donner des recommandations intelligentes pour affiner les modèles et l’acquisition de données. Contrairement aux grands fournisseurs de cloud, notre objectif est que vous ne consommiez que ce dont vous avez besoin pour construire des services numériques dans la solution. Pas moins. Pas plus.
En ce qui concerne le stockage brut, nous surveillons principalement la taille de la base de données. Comme mentionné précédemment, nous stockons les données qui ont été collecté sans les transformer. Ainsi, l’utilisation totale du stockage ne dépend que de :
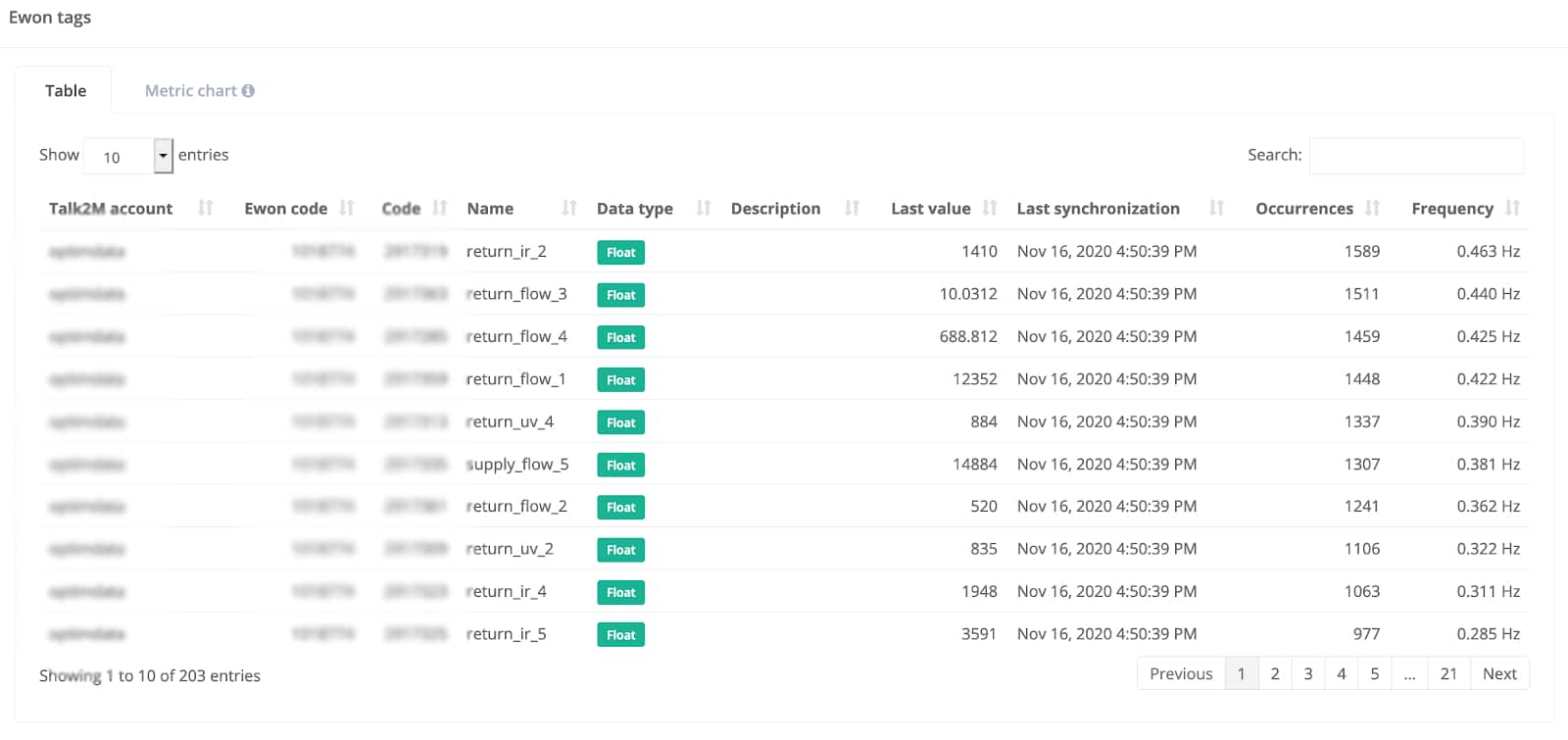
Grâce à notre connecteur natif pour les gateway Ewon Flexy, nous offrons des analyses spécifiques pour ce type d’acquisition de données. Nous surveillons pour chaque variable Ewon et chaque gateway Ewon la fréquence d’acquisition des données.
Pour rappel, Ewon fournit des gateway IoT qui se connectent aux automates et effectuent l’acquisition de données sur le cloud. Il existe plusieurs paramètres pour cette acquisition : par exemple, une variable peut être historisée en prenant une valeur toutes les X secondes et/ou lorsque le changement de valeur est supérieur à un seuil donné.
Les paramètres d’acquisition doivent être ajustés par variable afin d’éviter le sous-échantillonnage (et une mauvaise approximation du signal) ou le sur-échantillonnage (stockage inutile). Par exemple, il est généralement inutile de collecter la température interne de votre usine toutes les secondes. L’interface mettra en évidence les variables ayant un taux d’échantillonnage élevé et un faible taux de variation afin d’encourager une consommation optimisée des données.
L’objectif à long terme est de fournir ce type d’informations pour d’autres intégrations standard telles que le MQTT.
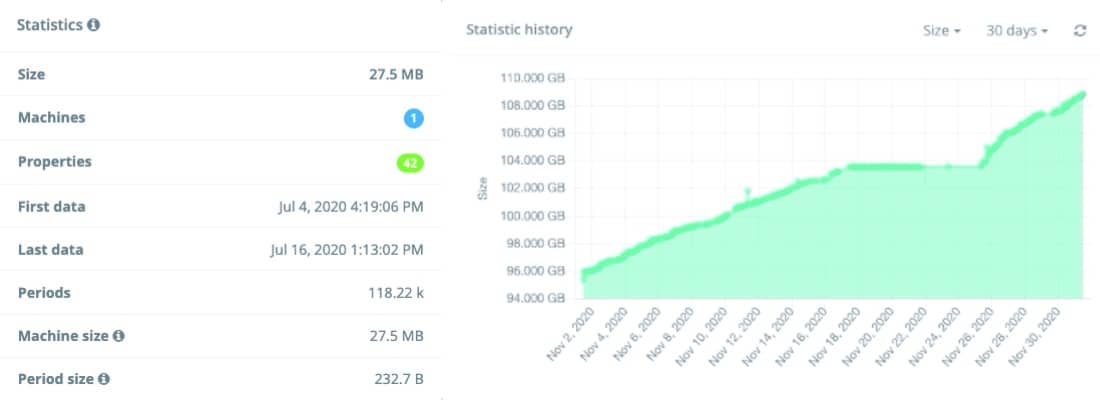
Pour les modèles, nous surveillons la taille de l’index Elasticsearch, le nombre de machines et de propriétés utilisées par le modèle, l’horodatage de la première et de la dernière date, le nombre de périodes (document Elasticsearch) et la taille moyenne par machine et par période. Ces statistiques sont historisées et peuvent être affichées sur plusieurs périodes.
Nous analysons également la manière dont les propriétés sont utilisées dans l’application et établissons des recommandations pour optimiser la taille du modèle :

Nous analysons également la manière dont les propriétés sont utilisées dans l’application et établissons des recommandations pour optimiser la taille du modèle :
Ces statistiques et informations peuvent aider l’utilisateur à :
La solution fournit un système complet de gestion des documents. Ainsi, vous pouvez :
Cette interface affichera la taille totale utilisée par ces fichiers.
Pour les modèles, nous surveillons la taille de l’index Elasticsearch, le nombre de machines et de propriétés utilisées par le modèle, l’horodatage de la première et de la dernière date, le nombre de périodes (document Elasticsearch) et la taille moyenne par machine et par période. Ces statistiques sont historisées et peuvent être affichées sur plusieurs périodes.
Allons plus loin
Comme vous pouvez le voir, ce nouveau module vous permet de surveiller et de prévoir simplement votre consommation de données. Il fournit également des recommandations intelligentes pour l’optimiser et notre équipe projets se fera un plaisir de vous aider à les mettre en œuvre.
Vous êtes intéressé(e) ? Vous voulez en savoir plus sur notre modèle de tarification ou sur ce module ? Nous serons heureux de vous donner une explication plus approfondie !
à lire également